[python] 백준 5525 - ioioi

백준 5525 - ioioi [SIVLER 1]
 벌써 프듀 시즌1이 7년 전이다?
벌써 프듀 시즌1이 7년 전이다?
문제
최초 입력 N이 들어오면, N+1 개의 I와 N개의 O가 교차로 나오는 문자열을 Pn이라 한다.
즉, IOI 는 P1, IOIOI는 P2를 의미한다.
N과 문자열 S의 길이, 그리고 문자열 S가 들어왔을 때, S안에는 Pn이 몇 개가 포함됐는지 출력한다.
딱 봐도 S의 0부터 순회하며 문자열을 일일히 검증하는 건 무조건 시간 초과가 생길 것 같은 문제다.
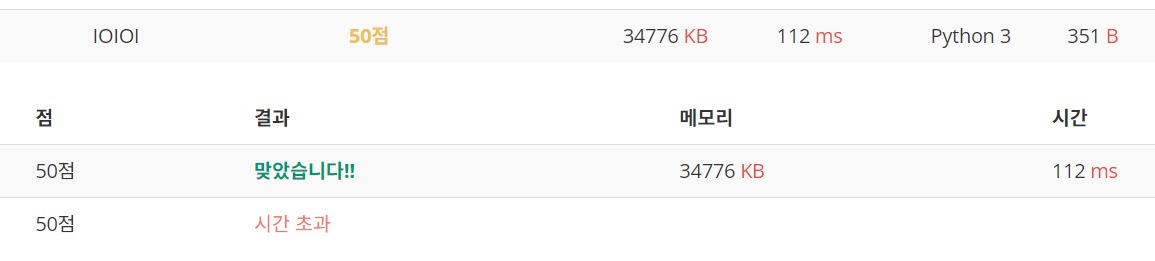
첫 번째 시도, 50점 짜리 정답
이번 문제는 제약 사항이 두 가지 버전이 있다.
| 배점 | 제한 |
|---|---|
| 50 | N ≤ 100, M ≤ 10 000. |
| 50 | 추가적인 제약 조건이 없다. N ≤ 1,000,000, M ≤ 1,000,000 |
즉, 원래 문제의 N이 100, M이 10,000 까지 있는 문제를 해결할 수 있는 코드는 50점 짜리 정답이 된다.
늘 그렇듯 이번에도 50점을 맞고 시작한다.

 엄마
엄마
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import sys, re
input = sys.stdin.readline
Pn = 'I'
N = int(input())
Pn += 'OI'*(N)
L = int(input())
S = input().strip()
dos = re.sub('O{2,}', '', S)
dis = re.sub('I{3,}', 'II', dos)
ans = 0
l = len(Pn)
i = 0
while i < len(dis):
if dis[i] == 'I':
if dis[i:i+l] == Pn:
ans += 1
i += 1
i += 1
print(ans)
위의 코드에서는 정규표현식을 활용해 O가 2연속 이상인 부분을 모두 삭제하고,
I가 3번 이상인 부분을 모두 II로 바꾸었다.
만약 N = 2이고 S = IOIIIOIOI일 때, Pn은 1번 등장하지만,
III를 I로 치환하거나, 없앨 경우 2번 또는 0번으로 바뀌기 때문이다.
이러한 발상은 좋았으나, (사실 정답에서는 크게 중요하지 않았기에, 오버헤드였을 뿐이다.)
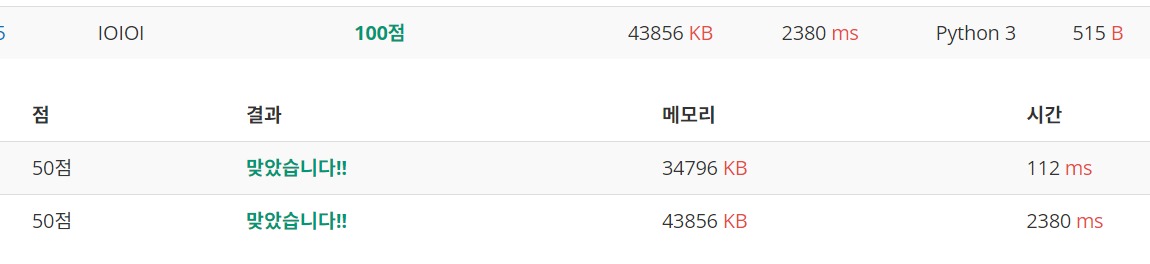
두 번째 시도, 대환장 리소스 파티
모든 인덱스를 훑는 다는 게 큰 문제였던 것 같다.
단순히 생각해서 1,000,000개의 문자열을 쭉 훑고
I가 보이면 일단 [index : index + len(Pn)]로 슬라이싱해서 매칭하다보니 빠를 수 없었다.
인덱스를 하나하나 증가하지 말고 쓸 데 없는 부분에선 도약할 필요가 있었다.
인덱스에 따라 문자열을 읽던 중 정답이 보이면
정답 끝부분 인덱스(index + len(Pn))로 건너가 +2까지에 OI가 붙어있는지 확인하는 식으로 식을 수정했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import sys, re
input = sys.stdin.readline
N = int(input())
Pn = 'i'+'OI'*(N)
L = int(input())
S = input().strip()
dos = re.sub('O{2,}', '', S)
dis = re.sub('I{3,}', 'II', dos)
ans = 0
l = len(Pn)
flag = 0
i = 0
while i < len(dis):
if flag:
if dis[i:i+2] == 'OI':
ans += 1
i += 1
else:
flag = 0
if not flag and dis[i] == 'I':
# 이 부분을 주목하자
if dis[i:i+l] == Pn:
# 여기까지 말이다.
i += l-1
ans += 1
flag = 1
i += 1
print(ans)
 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
 ㅋㅋㅋㅋ이럴 거면 오답처리 시키라고 아 ㅋㅋㅋㅋ
ㅋㅋㅋㅋ이럴 거면 오답처리 시키라고 아 ㅋㅋㅋㅋ
간신히 정답의 범주에 들긴 했으나 이걸 풀었다고 할 수는 없을 것 같다.
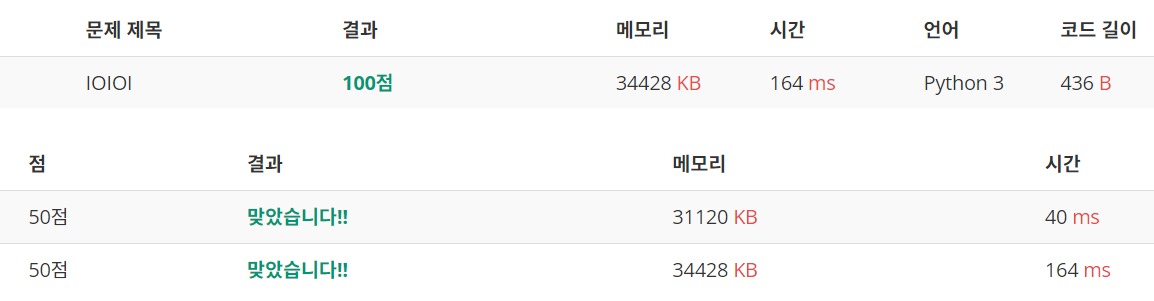
세 번째 시도, find()와 정답 코드
어떻게든 연산횟수를 줄일 방법을 찾으려고 했는데 답은 find 메서드였다.
Python의 많은 기본 메서드와 함수는 내부 로직이 C로 짜여진 경우가 많다.
Python으로 굳이 그것들을 직접 구현하면 손해다.
1
2
3
4
5
6
7
def find(string, target)
i = 0
while i < len(string):
if string[i: i+len(target)] == target:
return i
else:
return -1
위의 코드는 find()가 수행하는 연산을 python으로 짠 것이다.
그리고 두 번째 시도의 while문 내부에는 이와 비슷한 검색 코드가 있다.
즉, 그냥 그 부분만 find로 바꾸면 되는 것이었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import sys
input = sys.stdin.readline
N = int(input())
Pn = 'I' + 'OI'*(N)
L = int(input())
string = input().strip()
ans = 0
l = len(Pn)
flag = 0
i = 0
while i < len(string):
if flag:
if string[i:i+2] == 'OI':
ans += 1
i += 2
else:
flag = 0
else:
# 바뀐 부분은 사실상 여기 뿐이다.
i = string.find(Pn, i)
# find의 두 번째 인자는 검색을 시작할 index다.
# i를 계속해서 find로 찾아낸 index로 도약하면 된다.
if i == -1:
break
ans += 1
i += l
flag = 1
print(ans)
 드디어 정상적인 수준으로 들어왔다
드디어 정상적인 수준으로 들어왔다
python으로 직접 구현한 find를 그저 기존의 메서드를 사용했을 뿐인데 30배 빨라졌다.
위의 방법 이후로, 문자열 자체를 find로 찾아낸 인덱스까지 꾸준히 슬라이싱 하는 방법도 사용하여 속도를 점차 줄여나갔다.
그 과정에서 정규 표현식이 되려 오버헤드였다는 것을 깨닫고는 지워버렸다…
그런데,
비슷한 연산을 거치는 코드들이 구현체의 차이로 시간복잡도가 다르게 설정된다는 게…
시간 복잡도 계산이 더욱 어려워졌다…